1、概述
ZooKeeper是用于分布式应用程序的分布式协调服务。分布式应用程序可以基于zookeeper来实现用于同步,配置维护以及组和命名的更高级别的服务。它的设计易于编程,并使用了按照文件系统熟悉的目录树结构样式设置的数据模型。
众所周知,协调服务很难做到。它们特别容易出现诸如比赛条件和死锁之类的错误。ZooKeeper背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
ZooKeeper允许分布式进程通过共享的分层名称空间相互协调,该命名空间的组织方式类似于标准文件系统。名称空间由数据寄存器(在ZooKeeper看来,称为znode)组成,它们类似于文件和目录。与设计用于存储的典型文件系统不同,ZooKeeper数据保留在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。
Zookeeper 特点
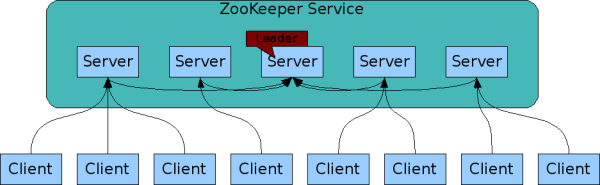
- Zookeeper : 一个领导者(Leader) ,多个跟随者(Follower) 组成的集群。
- 可靠性: 群集中只要有半数以上的节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器
- 全局数据一致性: 每个server保存一份相同的数据副本,Client 无论连接到哪个节点数据都是一致的。
- 顺序一致性: 来自客户端的更新将按照其发送顺序依次执行。
- 原子性: 数据更新要么成功要么失败。
- 实时性:在一定时间范围内,客户端能读到最新数据。
数据模型和分层名称空间
ZooKeeper提供的名称空间与标准文件系统的名称空间非常相似。名称是由斜杠(/)分隔的一系列路径元素。ZooKeeper命名空间中的每个节点都由路径标识。
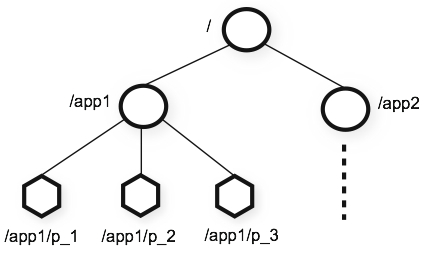
持久节点和短暂节点
ZooKeeper命名空间中的每个节点都可以具有与其关联的数据以及子节点。就像拥有一个文件系统一样,该文件系统也允许文件成为目录。(ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点上的数据通常很小,在字节到千字节范围内(1MB))每个节点称之为Znode。
Znodes维护一个统计信息结构,其中包括用于数据更改,ACL更改和时间戳的版本号,以允许进行缓存验证和协调的更新。znode的数据每次更改时,版本号都会增加。例如,每当客户端检索数据时,它也接收数据的版本。
原子地读取和写入存储在名称空间中每个znode上的数据。读取将获取与znode关联的所有数据字节,而写入将替换所有数据。每个节点都有一个访问控制列表(ACL),用于限制谁可以执行操作。
ZooKeeper还具有短暂节点的概念。只要创建znode的会话处于活动状态,这些znode就存在。会话结束时,将删除znode。

1)czxid-创建节点的事务zxid
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的事务zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
有条件的更新和监视
ZooKeeper支持watches的概念。客户端可以在znode上设置watches。znode更改时,将触发并删除监视。触发监视后,客户端会收到一个数据包,说明znode已更改。如果客户端和其中一个ZooKeeper服务器之间的连接断开,则客户端将收到本地通知。
3.6.0中的新增功能:客户端还可以在znode上设置永久的,递归的watches,这些watches在触发时不会被删除,并且会以递归方式触发已注册znode以及所有子znode的更改。
简单的API
ZooKeeper的设计目标之一是提供一个非常简单的编程界面。因此,它仅支持以下操作:
- create:在树中的某个位置创建一个节点
- delete:删除节点
- 存在:测试某个位置是否存在节点
- get data:从节点读取数据
- set date:将数据写入节点
- get children:获取节点子节点的列表
- sync:等待数据传播
应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
2、分布式集群搭建
| IP | HOSTNAME | 系统 |
|---|---|---|
| 64.115.3.30 | hadoop30 | centos7 |
| 64.115.3.40 | hadoop40 | centos7 |
| 64.115.3.50 | hadoop50 | centos7 |
- 安装JDK参考环境配置
- 最新版下载 zookeeper-3.7.0

- 下载解压
$ wget https://ftp.riken.jp/net/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
$ tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
- 创建数据目录
mkdir -p /data/zookeeper- 在数据目录下创建服务器编号文件myid
vim /data/zookeeper/myid
#注意: 该文件编号每台服务器不同,后面拷贝文件时不要忘记修改。
# 我这里 hadoop30 服务器编号为30,hadoop40 服务器编号为40,hadoop50 服务器编号为50
- 修改 zoo.cfg 文件
cd /software/apache-zookeeper-3.7.0-bin/conf/
# conf 这个路径下的zoo_sample.cfg修改为zoo.cfg
mv zoo_sample.cfg zoo.cfg
# 修改 zoo.cfg 文件
# 修改如下内容:
#数据目录
dataDir=/data/zookeeper
#集群配置
server.30=hadoop30:2888:3888
server.40=hadoop40:2888:3888
server.50=hadoop50:2888:3888
- 拷贝配置文件到其他机器
使用xsync 脚本同步文件 脚本
#同步Zookeeper安装包,配置
xsync /software/apache-zookeeper-3.7.0-bin
#同步数据目录,myid 文件
xsync /data/zookeeper文件同步后注意修改myid 服务器编号
- 启动集群
#每台服务器都执行一下
cd /software/apache-zookeeper-3.7.0-bin/bin/
./zkServer.sh start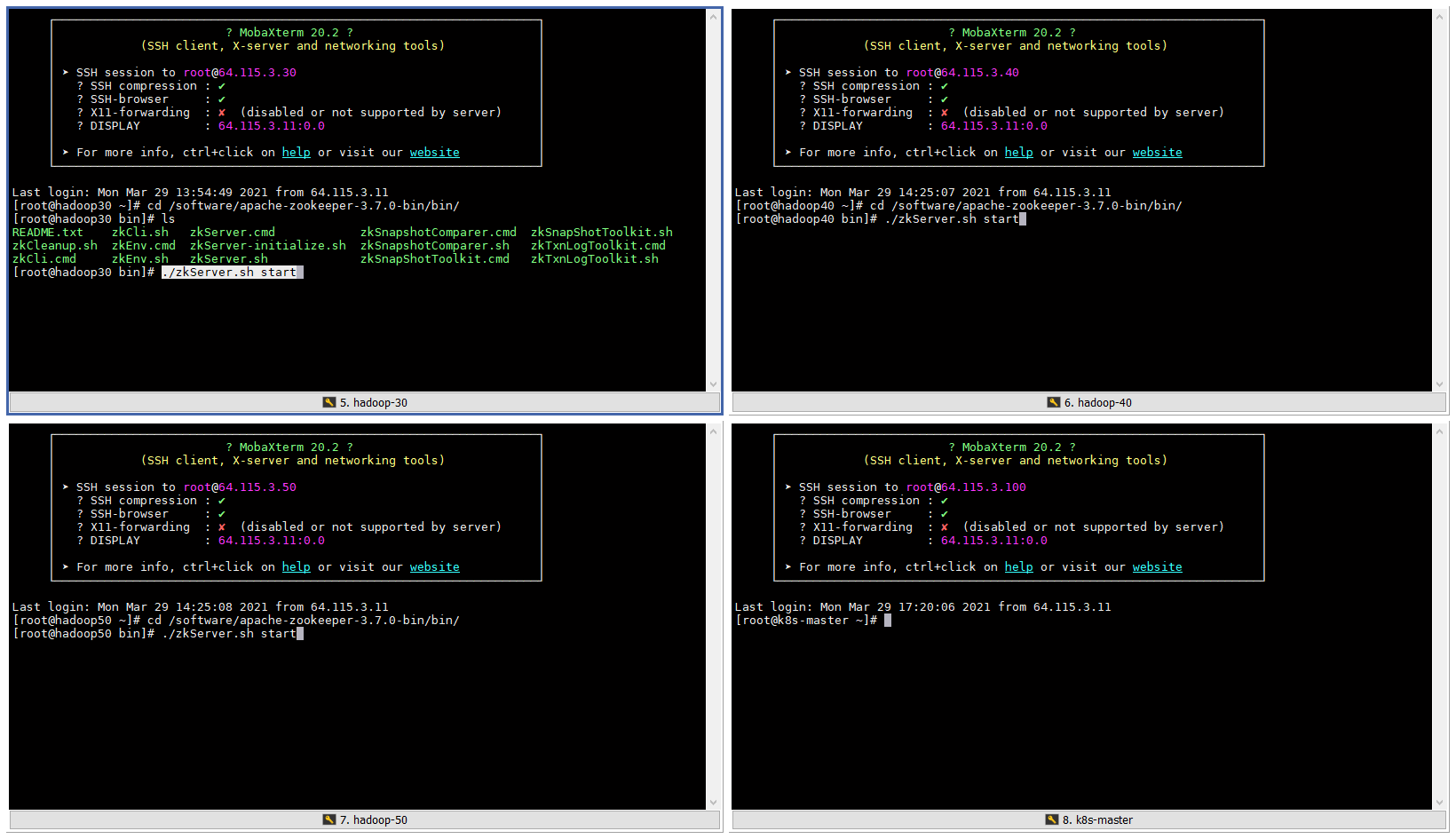
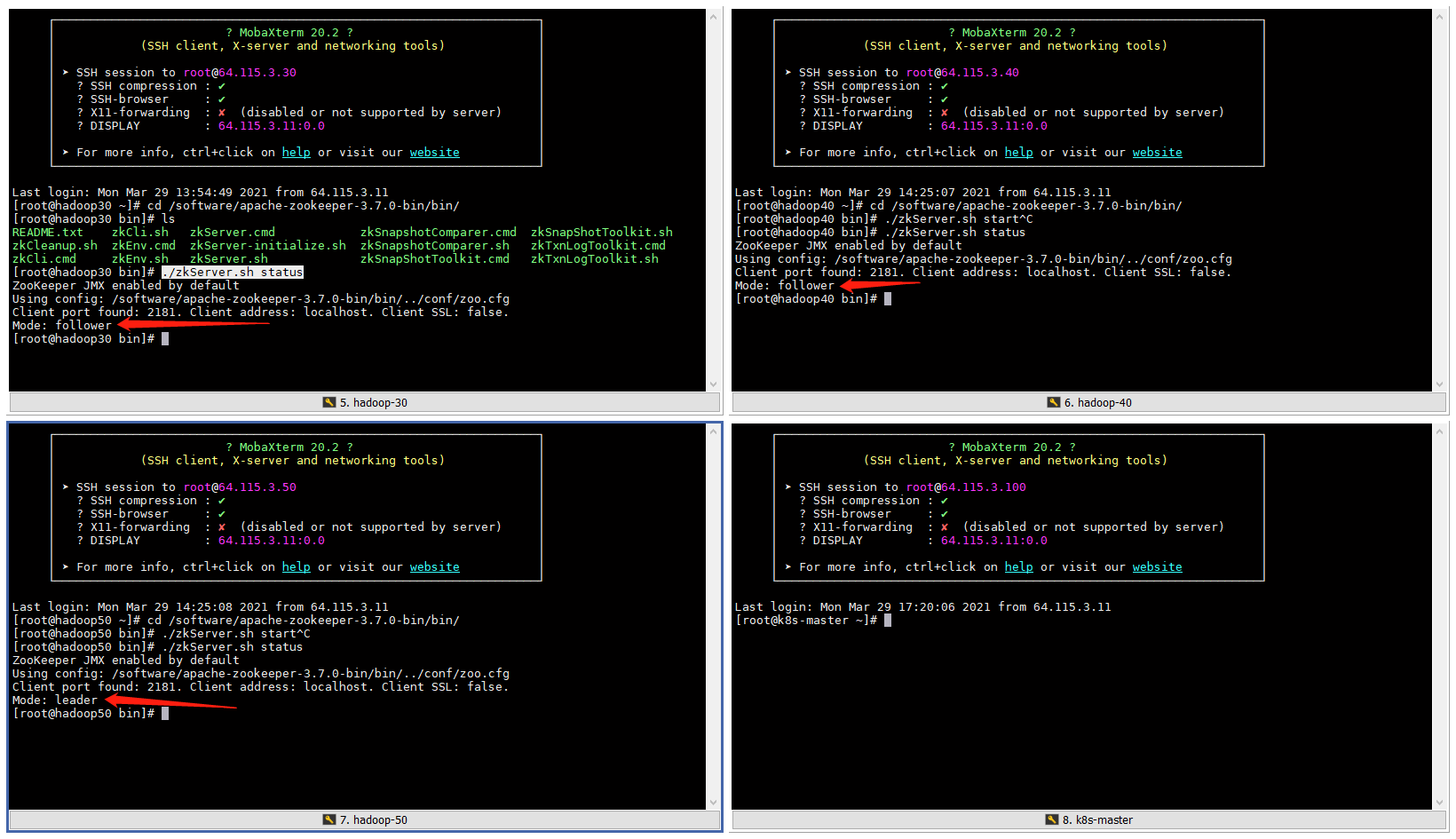
- 查看状态
./zkServer.sh status