
| IP | HOSTNAME | 启动服务 |
|---|---|---|
| 64.115.3.30 | hadoop30 | Namenode\Datanode\NodeManager |
| 64.115.3.40 | hadoop40 | SecondaryNameNode\Datanode\NodeManager |
| 64.115.3.50 | hadoop50 | ResourceManager\Datanode\NodeManager |
Namenode,SecondaryNameNode,ResourceManager 这三个服务都是比较吃内存的所以不放在一台服务器上,如果资源充足放一台服务器上也是没有问题的。 Namenode,SecondaryNameNode 是一个主备的关系最好不放在同一台机器上。
一、初始服务器
每台服务器都要修改,都是基本操作不细说下面举个例子
- 配置主机IP
$ vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=1fce55bf-9a16-45ab-abce-386039d76568
DEVICE=ens33
ONBOOT=yes
IPADDR=64.115.3.30
GATEWAY=64.115.3.1
NETMASK=255.255.255.0
DNS1=114.114.114.114
DNS2=8.8.8.8- 配置主机名称
hostnamectl set-hostname hadoop30- 配置域名解析
$ vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
64.115.3.30 hadoop30
64.115.3.40 hadoop40
64.115.3.50 hadoop50- 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld- 配置ssh 免密登录
我们在hadoop30 机器启动start-hdfs.sh 脚本需要配置 hadoop30 到其余机器的ssh免密登录。
在hadoop50 机器启动start-yarn.sh 脚本需要配置 hadoop50 到其余机器的ssh免密登录。
#hadoop30 服务器上执行
ssh-keygen
ssh-copy-id root@hadoop30
ssh-copy-id root@hadoop40
ssh-copy-id root@hadoop50
#hadoop50 服务器上执行
ssh-keygen
ssh-copy-id root@hadoop30
ssh-copy-id root@hadoop40
ssh-copy-id root@hadoop50
二、下载安装包,配置环境变量
我的软件安装目录是 /software
mkdir /software下载地址:
JAVA JDK : https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
HADOOP : https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
- 解压
tar -zxvf jdk-8u271-linux-x64.tar.gz
tar -zxvf hadoop-3.3.0.tar.gz
- 配置环境变量
$ vim /etc/profile 最后面追加以下内容#配置JAVA环境变量
export JAVA_HOME=/software/jdk1.8.0_271
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#配置hadoop环境变量
export HADOOP_HOME=/software/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
#配置自定义脚本xsync 环境变量
export PATH=/root:$PATH
- 编写脚本,用于后续同步文件
$ cd /root
$ vim xsync#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo "没有传递参数!"
exit;
fi
# 遍历群集所有机器
for host in 64.115.3.30 64.115.3.40 64.115.3.50
do
echo "============================= $host ==========================="
#遍历所有目录,挨个发送
for file in $@
do
#判断文件是否存在
if [ -e $file ]
then
#获取父目录
pdir=$( cd -P $(dirname $file ); pwd )
#获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo "$file 不存在!"
fi
done
done
#加个执行权限
$ chmod +x xsync三、修改Hadoop 群集配置
- 配置 hadoop-env.sh 末尾添加
$ vim hadoop-env.sh#设置为Java安装的根目录
export JAVA_HOME=/software/jdk1.8.0_271
export HADOOP_PID_DIR=/software/hadoop-3.3.0/tmp
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root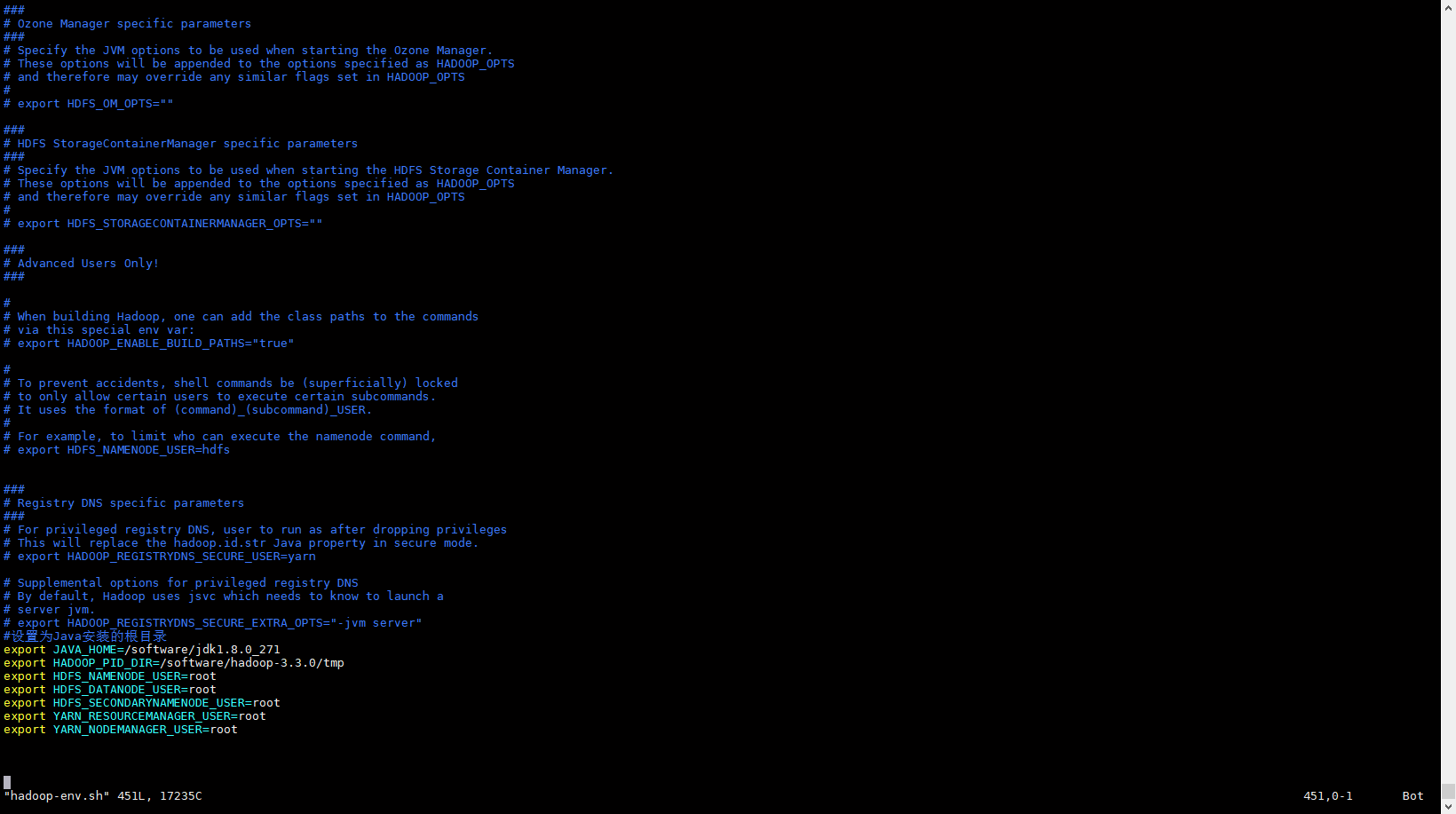
配置注意事项
1.JAVA_HOME的路径一定要填写绝对路径!2.HADOOP_PID_DIR的值可以先填上去,后面再去创建,创建的时候最好放在hadoop安装目录下,而且只需要创建到tmp文件夹就行,pids会自动生成,方便拷贝到其他节点(虚拟机)上
3.其余的KEY对应的值都是root,
- 配置core-site.xml文件
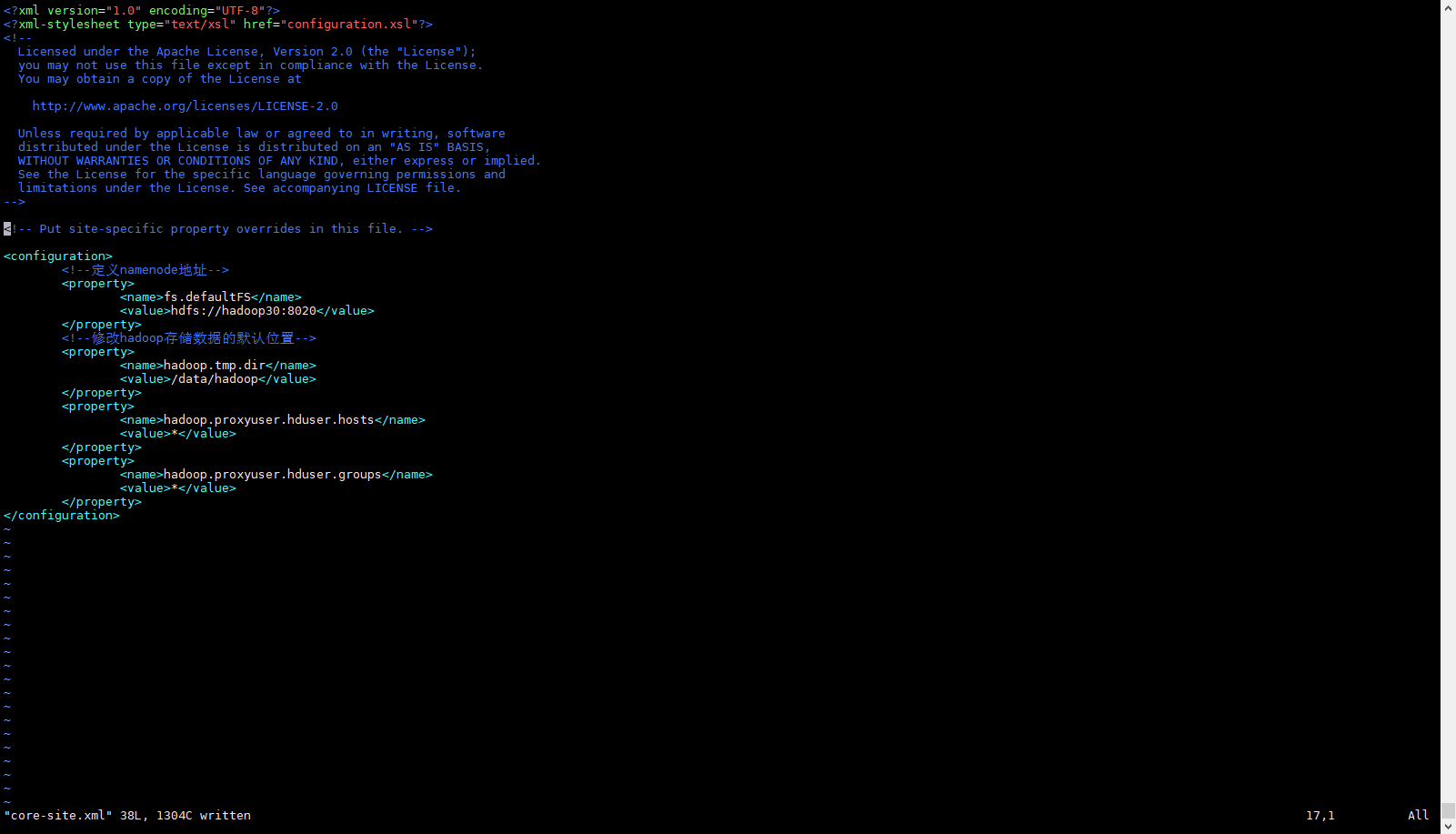
<configuration>
<!--定义namenode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop30:8020</value>
</property>
<!--修改hadoop存储数据的默认位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>配置说明
- 我们需要手动创建
/data/hadoop目录
- 配置hdfs-site.xml文件

<configuration>
<!--副本数 默认为 3 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode web 端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop30:9870</value>
</property>
<!-- secondarynamenode web 端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop40:9868</value>
</property>
</configuration>
配置说明
- 配置mapred-site.xml文件
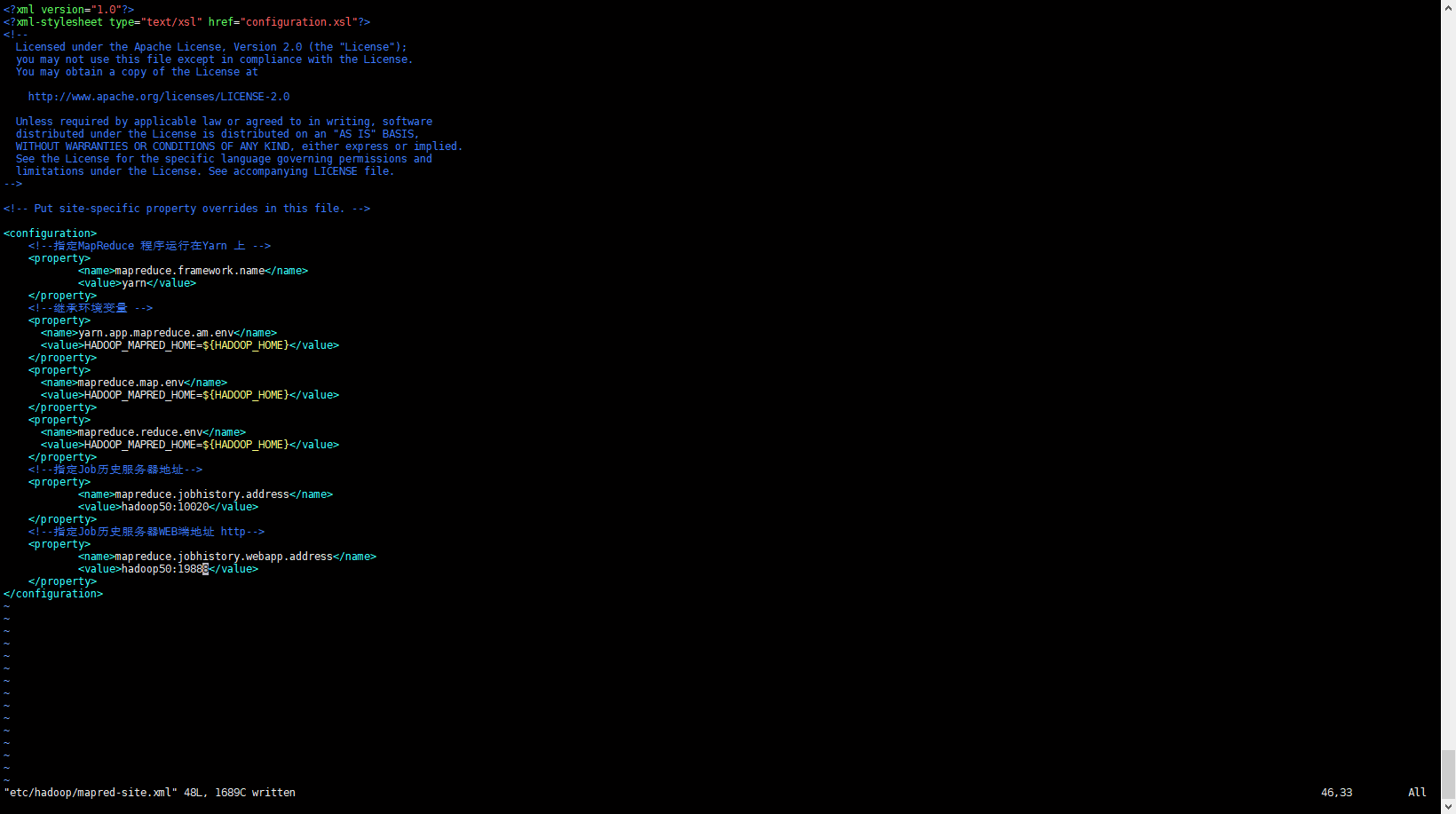
<configuration>
<!--指定MapReduce 程序运行在Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--继承环境变量 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--指定Job历史服务器地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop50:10020</value>
</property>
<!--指定Job历史服务器WEB端地址 http-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop50:19888</value>
</property>
</configuration>配置说明
- mapreduce.framework.name 配置yarn来进行任务调度
- 配置yarn-site.xml文件
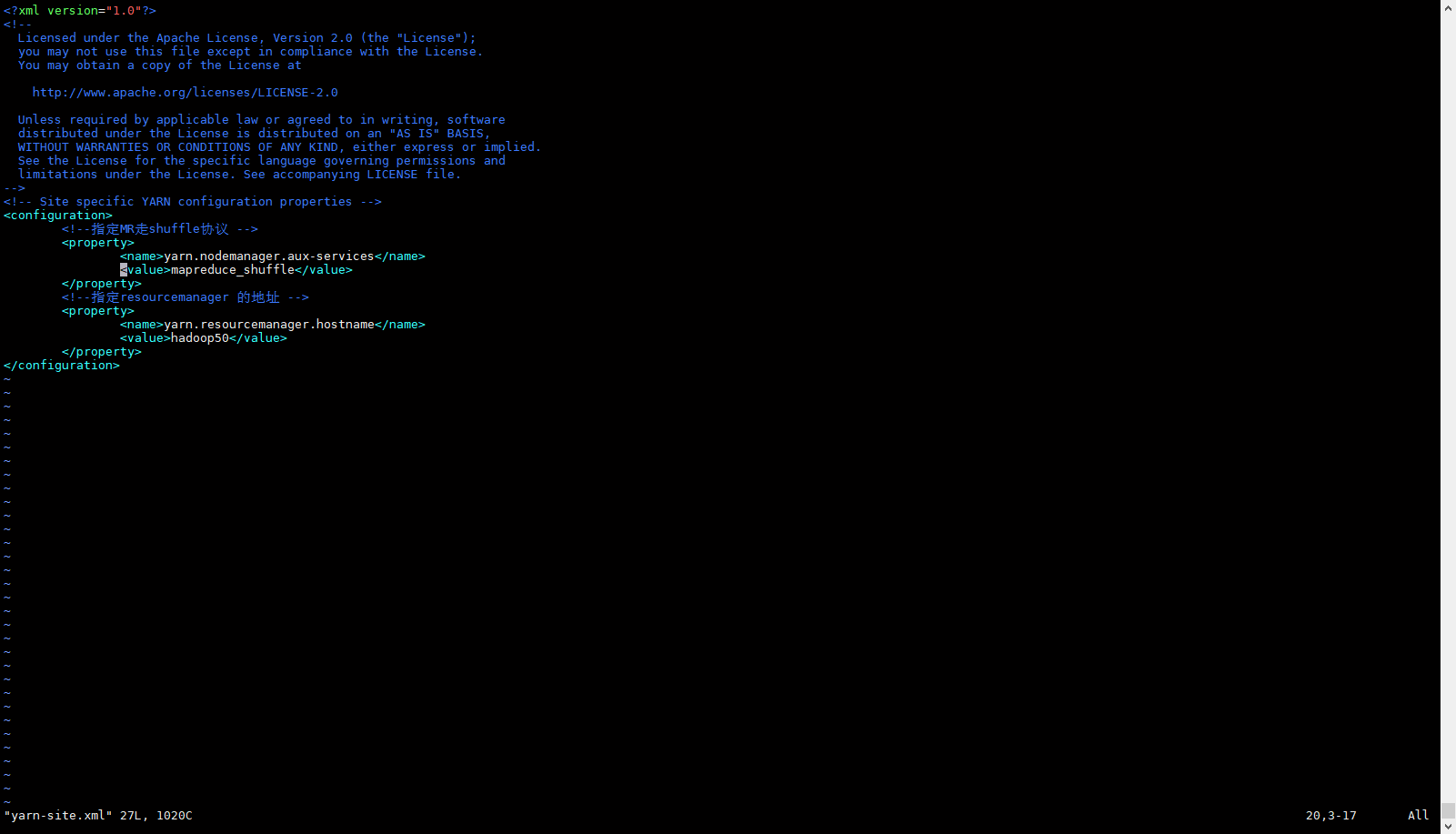
<configuration>
<!--指定MR走shuffle协议 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop50</value>
</property>
</configuration>配置说明
- yarn.resourcemanager.hostname 配置yarn启动的主机名,启动yarn 时 要在hadoop50 这台机器启动。
- 配置workers文件

hadoop30
hadoop40
hadoop50配置说明
workers 配置的是datanode工作的机器,datanode主要是用来存放数据文件的,datanode 可以和namenode在同一台机器,也可以namenode 单独一台机器。
- 复制hadoop到其余机器
配置文件修改好之后,可以用编写好的xsync 脚本,将hadoop 复制到其余机器。
我之前同步过一次了。所以说下面截图同步的内容比较少,如果第一次同步可能文件比较多。

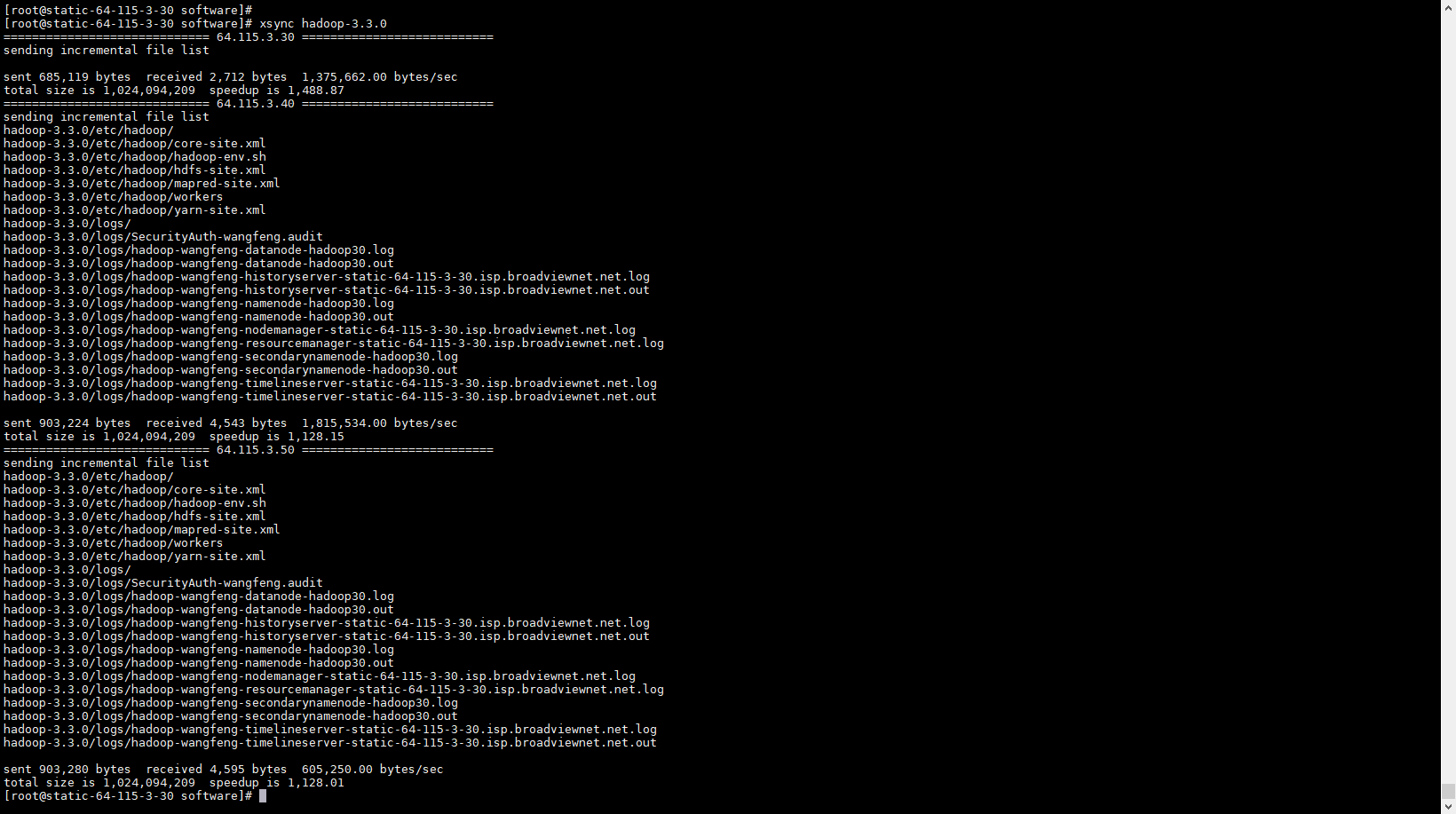
四、启动集群
第一次启动HDFS时,必须对其进行格式化。将新的分布式文件系统格式化
#在hadoop30 服务器执行
$ hdfs namenode -format 
初始化之后会在数据目录生成初始化文件

-
使用脚本启动HDFS进程。
start-dfs.sh
查看进程
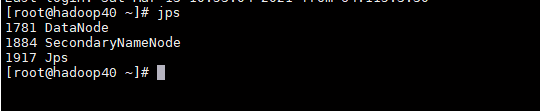
正常启动hadoop30 服务器上应该有 DataNode 和 NameNode 两个进程,
hadoop40 服务器上有DataNode 和 SecondaryNameNode 两个进程,
jps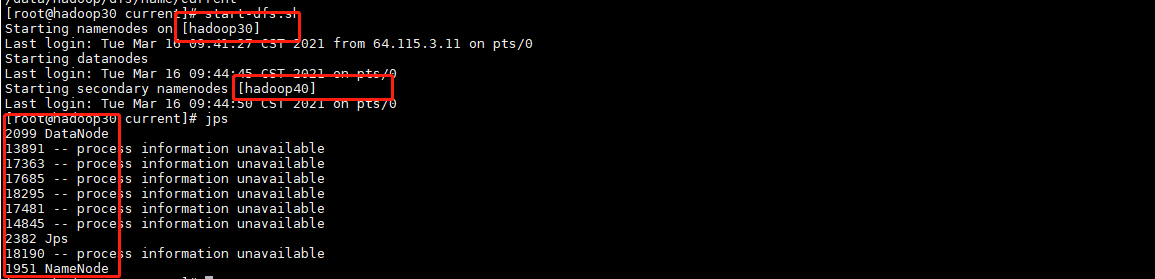
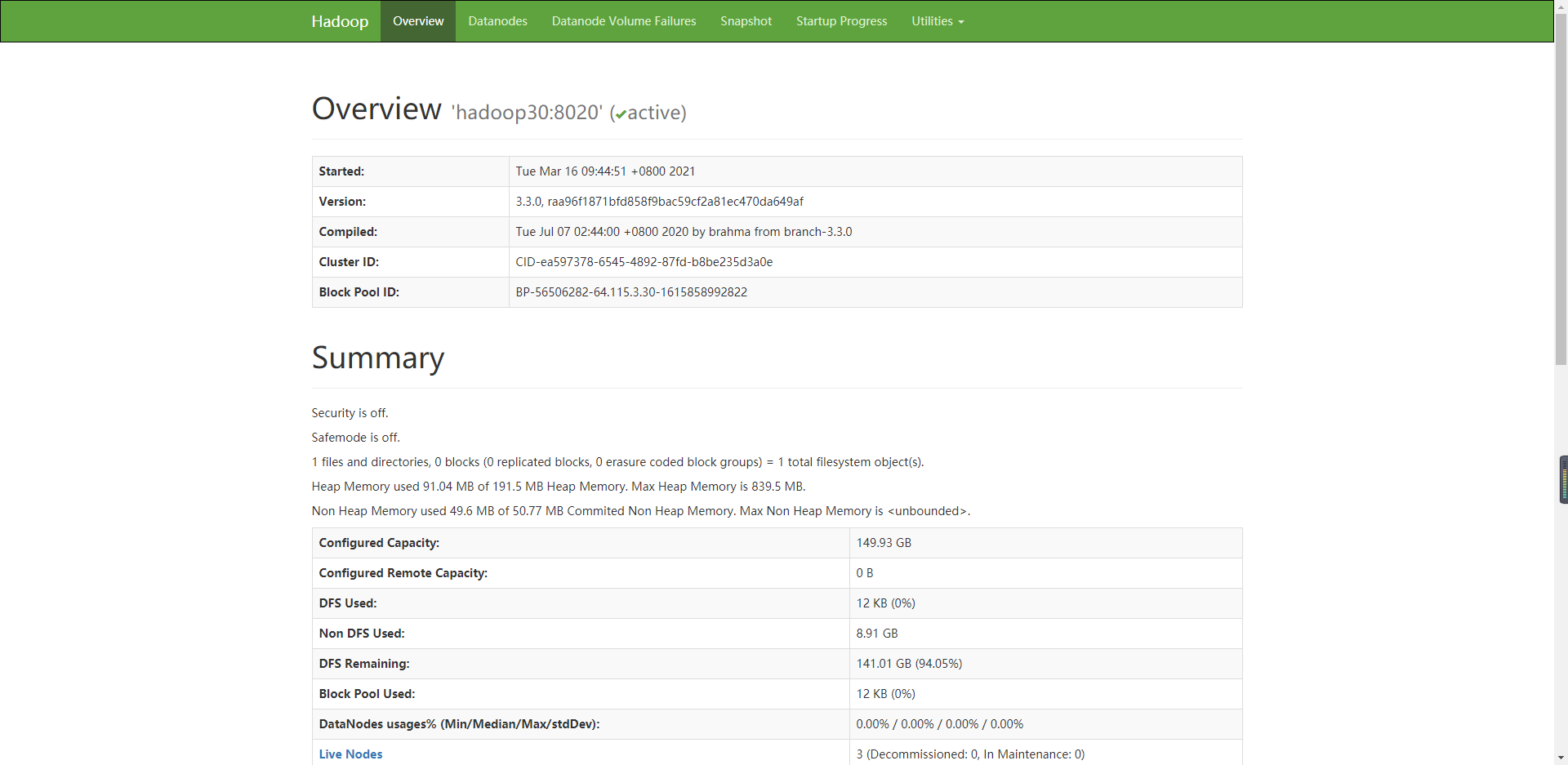
访问DHFS NameNode Web 端
-
使用脚本来启动YARN进程
我们指定ResourceManager 在hadoop50 服务其上运行,所以说启动yarn 的时候需要在hadoop50 服务器上执行启动脚本
start-yarn.sh
使用以下命令启动MapReduce JobHistory Server,并在指定服务器上以mapred运行:
mapred --daemon start historyserver- jps 检查所有进程



访问Yarn Web 端

访问MapReduce JobHistory Server

五、Web界面
Hadoop集群启动并运行后,如下所述检查组件的Web UI:
| 守护进程 | 网页界面 | 笔记 |
|---|---|---|
| NameNode | http:// nn_host:port / | 默认的HTTP端口是9870。 |
| ResourceManager | http:// rm_host:port / | 默认的HTTP端口为8088。 |
| MapReduce JobHistory Server | http:// jhs_host:port / | 默认的HTTP端口是19888。 |
- 停止服务命令
#停止HDFS
stop-dfs.sh
#停止Yarn
stop-yarn.sh
#停止历史服务
mapred --daemon stop historyserver